人工智能是目前最炙手可热的话题,泡沫非常明显,然而中美欧日四大央行都疯狂放水,各种资产泡沫都极为明显,所以人工智能这个泡沫也不算很大。人工智能最终还要芯片来承载,软件和硬件是分不开的。
说到芯片就需要说到晶圆代工行业,除英特尔和三星外,全球绝大多数的数码类芯片都是晶圆代工厂制造的,华为、高通、苹果、英伟达、AMD、NXP、谷歌、微软、IBM这一系列科技领域的巨头都离不开晶圆代工厂,还包括英特尔。
虽然英特尔先进制程能力丝毫不次于台积电,然而那只是CPU领域,英特尔收购了FPGA大厂Altera,Altera的FPGA依然是台积电独家代工。深度学习及人工智能(AI)是2017年美国消费性电子展(CES)重头戏之一,英特尔为AI推出的Intel Nervana平台将在2017年内陆续推出。英特尔依然要与台积电合作,Altera Arria 10可程序逻辑闸阵列(FPGA)的深度学习加速卡(DLIA)由台积电20纳米代工,Lake Crest处理器的类神经网路加速平台由台积电28纳米代工。两个关键的芯片还是由台积电代工,实际上Xilinx在制程上一直领先Altera,背后原因就是台积电。台积电2016年毛利率为50.1%,营业利润率为39.9%,净利率38%,英特尔的毛利率60.9%,营业利润率21.7%,净利率是17.3%。台积电比英特尔的净利率高出很多。
晶圆代工行业的技术含量丝毫不次于芯片设计,甚至高于芯片设计,人工智能芯片由晶圆代工业者掌控,而非芯片设计者。这就像美国人最早发明了CCD,然而将其工业化量产的是索尼,虽然CCD已是昨日黄花,但是全球能量产CCD的只有日本厂家,没有一个美国厂家能够量产,这也奠定了日本在CCD数码相机时代绝对的霸主地位。
10纳米还是7纳米?
为什么数字芯片需要不断追随先进制程?所谓制程纳米,是CMOS FET晶体管闸极的宽度,也就是闸长。闸长可以分为光刻闸长和实际闸长,光刻闸长则是由光刻技术所决定的。由于在光刻中光存在衍射现象以及芯片制造中还要经历离子注入、蚀刻、等离子冲洗、热处理等步骤,因此会导致光刻闸长和实际闸长不一致的情况。另外,同样的制程技术下,实际闸长也会不一样,比如虽然三星也推出了 14nm 制程芯片,但其芯片的实际闸长和 Intel 的 14nm 制程芯片的实际闸长依然有一定差距。
闸长越短,有两大好处,一是可以提高晶体管密度,在同样大小的硅晶圆制造更多的晶体管,需要的运算资源越强,对应的晶体管数量就越多。英伟达的Xavier Tegra处理器号称是“全球第一个AI汽车超级芯片”,将采用台积电16nm FinFET+工艺制造,集成多达70亿个晶体管。性能方面,Xavier预计可以达到30 DLTOPS,比现在的Drive PX 2平台提高50%,同时功耗只有30W。拥有多达八个NVIDIA自主设计的ARMv8-A 64位CPU核心,GPU则会基于下一代“Volta”(伏特)架构,最多512个流处理器,还有基于硬件的视频流编码解码器,最高支持7680×4320 8K分辨率,以及各种IO输入输出能力。
英伟达还有一片GTX 1080 TI,同样采用台积电16nm FinFET+工艺制造,集成多达120亿个晶体管,硅片面积是471平方毫米。英特尔至强E5 2600 V4,引入了14nm工艺,456平方毫米的核心面积里集成了72亿个晶体管,相比之下上代22nm Haswell-EP Xeon E5-2600 v3只有56.9亿个晶体管,而核心面积达662平方毫米。
英伟达专为深度学习订做的芯片Tesla P100,则在600平方毫米内集成了150亿个晶体管,仍然是台积电的16nm FinFET+工艺制造,单精度浮点运算能力达9.3TFLOPS。高通的骁龙835则是集成了30亿个晶体管,
闸长的短的另一个好处是降低功耗。
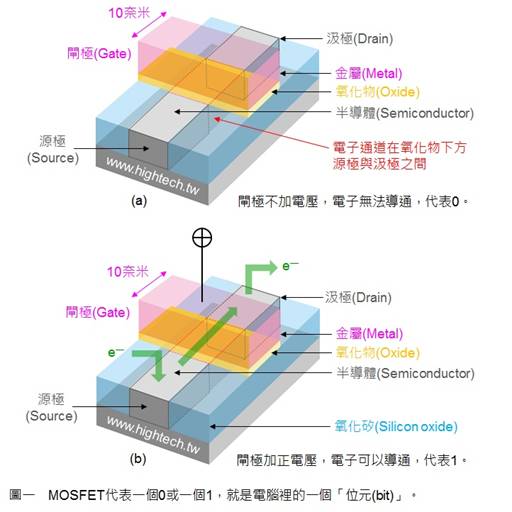
电流从 Source(源极)流入 Drain(漏级),Gate(闸极)相当于闸门,主要负责控制两端源极和漏级的通断。电流会损耗,而栅极的宽度则决定了电流通过时的损耗,表现出来就是手机常见的发热和功耗,宽度越窄,功耗越低。
业内公认,10纳米不是关键,关键是7纳米,10纳米只是低功耗过渡工艺,性能上与14纳米相差无几,意义不大,7纳米才是关键之战。相关下游业者也表示,未必会使用10纳米产品,如20纳米为16纳米制程之过渡期产品,反而7纳米才是下一代锁定的主力目标。
从ARM的态度也能看出7纳米才是重点。2016年3月,ARM和台积电宣布签订针对7纳米FinFET工艺技术的长期战略合作协议,涵盖了未来低功耗,高性能计算SoC的设计方案。该合作协议进一步扩展了双方的长期合作关系,并将领先的工艺技术从移动手机延伸至下一代网络和数据中心。ARM全球执行副总裁兼产品事业群总裁Pete Hutton表示:“现有基于ARM的平台已展现提升高达10倍运算密度的能力,用以支持特定数据中心的工作负载。未来的ARM技术将适用于数据中心和网络基础设施,并针对台积电7纳米 FinFET进行优化,从而帮助我们共同的客户将行业最低功耗的架构应用于不同性能要求的领域。”
ARM当然不是只说说而已,2017年3月21日,ARM在北京宣布推出面向人工智能领域的全新的DynamIQ技术,为AI的多核处理迈出一大步。DynamIQ技术在业界被称为是面向未来ARM Cortex-A系列处理器的基础,代表了多核处理设计行业的转折点,其所具有的灵活多样性将重新定义更多类别设备的多核体验,覆盖从端到云的安全、通用平台。在此背景下,DynamIQ技术能被广泛应用于汽车、家庭以及数不胜数的各种互联设备,这些设备所产生的以泽字节(ZB,一泽字节大约等于1万亿GB)为计算单位的数据会在云端或者设备端被用于机器学习,以实现更先进的人工智能。
针对机器学习(ML)和人工智能(AI)的全新处理器指令集:第一代采用DynamIQ技术的Cortex-A系列处理器在优化应用后,可实现比基于Cortex-A73的设备高50倍的人工智能性能,并最多可提升10倍CPU与SoC上指定硬件加速器之间的反应速度。DynamIQ技术为ADAS解决方案带来更快的响应速度,并能增强安全性,确保合作伙伴能够设计ASIL-D合规系统,即使在故障情况下仍然能够安全运行。
当然这一切都离不开台积电的7纳米。
三星、台积电、英特尔三方恶战
道德经有句话,企者不立,跨者不行。还有句话是欲速则不达。三星就是最典型的例子,三星总想跳跃式发展,超过台积电。
在十四/十六纳米竞争时代,即使三星领先台积电六个月量产,且有较细的硅间闸(contacted gate pitch,台积电规格为九十纳米、三星为七十八纳米);但其输在稳定良率、成本控制、产能和布线等方面。而在十纳米时代,三星的同步量产,就更无法扭转这个劣势。在七纳米时代,三星和英特尔应会卷土重来,但败象仍高。高通会将90%的七纳米先进制程订单,从三星转回台积电。
为何台积电总能在先进制程屡战屡胜呢?首先也是最重要的一点,台积电从来不会试图跳跃式发展,一步一步来。其次不像其他竞争者,与台积电无利益冲突的客户群(苹果、赛灵思、英伟达、博通/安华高、瑞萨、谷歌、海思、联发科)数量庞大,不断地追求先进制程,投入研发,改善设计规则,与台积电共同改善制程良率、降低成本,来加快量产速度;也就是说,台积电背后有着全球所有最顶尖的IC设计公司在支持。而且台积电有超过50%产能,已完全折旧、做成熟制程;而且五年折旧的新机器设备,约可使用十五年以上,这样可提供足够的现金流,来大量投资初期获利较差的最先进制程。而三星和英特尔因不具备足够晶圆客户,三星和英特尔尽量将旧制程转换成新制程(机器设备多使用三至五年),并利用主流产品(三星的内存,英特尔的中央处理器)现金流,来补助晶圆代工的投资;因此三星会出现亏损,英特尔的营业利润率和净利率会远远落后台积电。台积电则使用其优异的布线,来微缩芯片尺寸和加快速度,而不是一味追求最小硅间闸和金属间闸(metal pitch or interconnects),进行可能威胁顺利量产的微缩。
英特尔也深知晶圆代工这个领域与台积电竞争无异于自杀,与台积电合作是双赢之路。论制程技术,英特尔当然还是全球第一,不过台积电与英特尔之间的差距越来越小。在过去14╱16纳米竞争时代,尽管英特尔对Altera14纳米生产晶圆出货,落后赛灵思(Xilinx)使用台积电16纳米出货数月之久,英特尔还是不断强调,其14纳米同样晶体管数量的芯片大小比台积电16纳米小30%以上,并有较佳的速度和耗电表现, 估计英特尔有22%较窄的硅间闸(TSMC’s 90vs. Intel’s 70纳米)和19%较小的金属间距(interconnects, TSMC’s 64 vs. Intel’s 52纳米)。到10纳米步入量产,台积电应会足足领先英特尔x86 CPU量产长达半年以上,只是台积电的芯片还是比英特尔大10-20%左右。
但到了7纳米时代,台积电应会于2018下半年开始量产苹果手机A12芯片,并足足领先英特尔7纳米量产时程超过两年。换句话说,台积电有史以来第一次有机会于2020下半年,用5纳米强压英特尔于2021年的7纳米量产。 台积电5纳米制程在硅间闸(44纳米)、金属间距(32纳米)、同样数量晶体管的芯片大小,速度与英特尔7纳米不相上下,在耗电表现、稳定良率、成本控制、产能和布线等方面,已经略优于英特尔。
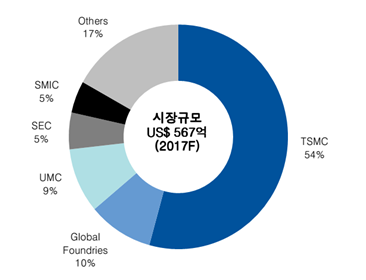
预计全球晶圆代工市场规模567亿美元,台积电市场占有率超过50%,而在28纳米以下的先进制程市场,台积电市场占有率超过85%,16纳米超过95%。大陆厂家SMIC则远远落后台积电,2016年28纳米工艺仅占其总收入的1.6%,而台积电的28纳米及28纳米以下工艺所占总收入的比例是54%,2017年1季度更逼近60%。三星在规模方面不及台积电的10%。
7纳米时代,台积电的市场占有率可能超过90%。不管你是谷歌还是IBM,人工智能芯片都得看台积电的脸色。台积电肯定会优先照顾大客户,像高通,海思,苹果,联发科这样出货量上亿的客户,至于人工智能芯片,得排队等着。
人工智能芯片价格会逐渐降低吗?
半导体硬件需要长期持续的投入,不是靠收购或挖人能够建立技术体系的,这需要几十年的技术积累。
大部分人都以为芯片价格当然是逐渐降低的,2014年以前可以算正确,2014年后就不对了。一是芯片制造这个领域市场集中度越来越高,先进制程领域,基本上由台积电垄断。台积电从不担心订单,订单都排队数年,甚至很多愿意提前付全额现金,台积电会维持产能平衡,并且28纳米以下晶圆代工领域,产能扩张非常困难。二是先进工艺带来了高成本,就像前面所说的英伟达的P100,英伟达声称开发成本高达20亿美元。28纳米工艺以后,IC设计公司的成本不断上升。
据Gartner估算,设计公司开发一款7纳米工艺的芯片,总成本将在2.7亿美元左右,差不多是28纳米开发成本的9倍。(注:现在Gartner估算14纳米开发总成本在8000万美元左右,去年一份报告中估算是2亿美元)。开发成本高了,然而产品的生命周期却短了,像苹果的A系列芯片,生命周期不超过3年。这就需要更高的售价来弥补。
芯片制程越先进,产能就越难扩展。
当晶体管闸极宽度缩小至65纳米左右时,却发现小于193纳米波长的光学微影技术相当困难,因此开始把晶圆泡在水中进行微影,这就是液浸微影技术。由于水的折射率高,193纳米的光由空气进入水中,其波长会再度降低,有利微影图案的真实性。不过,今日晶体管闸极已缩小至20纳米左右,比193纳米小了约10倍,电路布局图案印到晶圆上产生非常严重的扭曲现象。为解决这问题,便研究利用接近X光波长的极端紫外光来微影,使用的是波长13纳米的紫外光,而能大幅改进微影图案的质量。
极紫外光(EUV)技术能印出极精细高质量的纳米级图形,但曝光速度没有传统微影技术快。极端紫外光技术利用雷射光照射真空中熔化的金属锡,其散射出的光波恰好是13纳米。而这种方式产生的光的强度十分微弱,因此曝光时间较传统微影长,对量产不利。产能提升非常困难,需要非常大的资金投入。EUV光刻机一台要一亿欧元。
内存上涨就表明,先进工艺制程并不会降低价格。
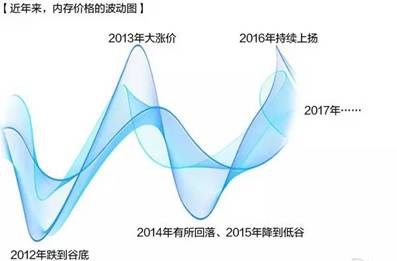
2012年前后大白菜价、2013年大涨价、2014年有所回落、2015年降到低谷、2016年持续上扬,2017年……。2017年,仅仅用了不到1个月时间,内存整体价格就上涨幅度超18%,涨价之凶猛多年未见了。SSD更疯狂,小厂家根本拿不到货。你会说这是短期现象,的确,大幅度上涨是短期现象,但是指望价格下降是别想了,芯片的价格已经是易涨难跌,主要还是产业集中度越来越高,竞争激烈程度下降了很多,厂家没有降价的动机。
同时,需求持续增加,看看英伟达的财报就知道,数据中心的收入增幅惊人。再有就是先进工艺良率提升困难,3D NAND已经提出5年了,厂家摸索了也超过3年,但良率依然很低,导致产出有限,因此大幅度上涨就不足为奇了。
中国角色
要衡量一个地区或国家半导体领域的投入,最简单的方法莫过于看荷兰ASML的订单,荷兰ASML垄断了晶圆厂最关键的设备光刻机的市场,也只做光刻机。在40纳米时代以前,日本的佳能和尼康还有能力生产光刻机,40纳米以下就只有ASML能够做了,完全垄断了市场。也就是说,你要新建40纳米以下的晶圆厂就必须提前(通常要提前半年到一年)向ASML订货,全球仅此一家。顺便说下,ASML的光刻机是全球最贵的设备,一套EUV光刻机要价一亿欧元。一套EUV光刻机的大小大约是一套60平米的一室一厅的体积。
上图为ASML 在2017年1月手中订单的地区分布状况,可以看出中国市场所占比例甚微。中国半导体领域高达数千亿的投资,似乎还没有投到关键点上。