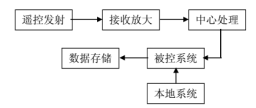
数字集成电路的设计可以分为系统级、行为级、结构级、RTL级、门级、电路级和版图级。系统级是把各个部件联系为一个有机的整体。比如一个射频系统如下图:
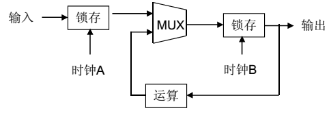
行为级就是实现何种功能,如FCW的行为级,根据摄像头的数据测算前方障碍物与自车之间的距离,并结合自车速度数据,计算出TTC时间。如果TTC时间低于阈值(通常是2.7秒)就报警,反之就不报警。RTL级就是寄存器级,如图
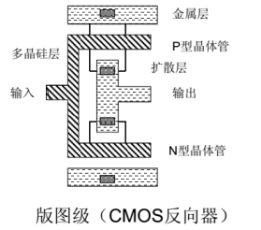
寄存器由逻辑门构成,逻辑门由电路构成,最后电路由半导体晶体管P和N结构成。
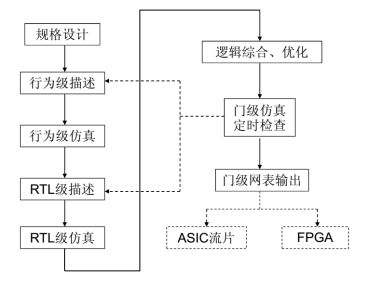
下图为数字类芯片设计的简单流程图:
目前集成电路设计基本上都是用IP核搭积木的形式。IP核分为行为(Behavior)、结构(Structure)和物理(Physical)三级不同程度的设计,对应描述功能行为的不同分为三类,即软核(Soft IP Core)、完成结构描述的固核(Firm IP Core)和基于物理描述并经过工艺验证的硬核(Hard IP Core)。软核就是我们熟悉的RTL代码;固核就是指网表;而硬核就是指指经过验证的设计版图。ARM还是以软核为主的。
IP软核(Soft IP Core):通常是用硬件描述语言(hardware Description Language,HDL)文本形式提交给用户,它经过RTL级设计优化和功能验证,但其中不含有任何具体的物理信息。据此,用户可以综合出正确的门电路级设计网表,并可以进行后续的结构设计,具有很大的灵活性,借助于EDA综合工具可以很容易地与其他外部逻辑电路合成一体,根据各种不同半导体工艺,设计成具有不同性能的器件。其主要缺点是缺乏对时序、面积和功耗的预见性。而且IP软核以源代码的形式提供的,IP知识产权不易保护。
IP硬核(Hard IP Core)是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件。由于无需提供寄存器转移级(Register transfer level,RTL)文件,因而更易于实现IP保护。其缺点是灵活性和可移植性差。IP固核(Firm IP Core)的设计程度则是介于软核和硬核之间,除了完成软核所需的设计外,还完成了门级电路综合和时序仿真等设计环节。一般以门级电路网表的形式提供给用户。
如果以FPGA来承载算法,那相对ASIC要简单的多。首先要了解FPGA的基本核心,就是LUT。每一块FPGA芯片都是由有限多个带有可编程连接的预定义源组成,可实现可重配置数字电路和I/O模块并允许电路接触外部环境。
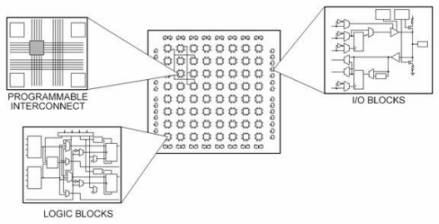
FPGA 说明书中通常介绍了可编程逻辑模块的数量、固定功能逻辑模块(如乘法器)的数目及存储器资源(如嵌入式块RAM)的大小。FPGA芯片中还有很多其它的部分,但是以上指标通常是在为特定应用选择和比较FPGA时的最重要参考指标。可重配置逻辑模块(configurable logic block, CLB)是FPGA的基础逻辑单元。CLB有时又称为片(slice)或逻辑单元,由两个基本元器件构成:触发器和查找表(LUT)。不同FPGA产品系列的区别在于触发器和LUT的组合方式,因此理解触发器和LUT是至关重要的。可重配置逻辑模块(CLB)中的大部分逻辑是以LUT的形式通过使用少量的随机存取存储器(RAM)来执行。我们可以简单地假定FPGA中系统门的数量是指特定芯片中与非门(NAND)以及或非门(NOR)的数量。但实际上,所有的组合逻辑(与门、或门、与非门、异或门等)都是通过查找表存储器中的真值表来执行。真值表是每个输入值组合对应的输出预定义表。简单的说,每一个LUT可以看成一个有4位地址线的16x1的RAM。当用户通过原理图或HDL语言描述了一个逻辑电路以后,PLD/FPGA开发软件会自动计算逻辑电路的所有可能的结果,并把结果事先写入RAM。这样,每输入一个信号进行逻辑运算就等于输入一个地址进行查表,找出地址对应的内容,然后输出即可。这就是FPGA为什么运行频率不高,却速度飞快的原因,它不像CPU或GPU那样用运算单元运算,它是像RAM那样读取的,自然速度远比CPU或GPU快。不过缺点也来了,如果运算量比较大,那么就需要比较多的LUT,对FPGA来说只能加大硅片面积,这会导致成本飞速增加。同时,FPGA只适合整数运算,传感器领域多小数运算,这时候通常需要加一个DSP硬核或软核,这当然会增加成本。现在的FPGA都不是纯粹的FPGA,都要加入一些DSP、CPU、时钟等构成一个SoC FPGA。
目前大部分FPGA都是基于SRAM工艺的,而SRAM工艺的芯片在掉电后信息就会丢失,一定需要外加一片专用配置芯片,在上电的时候,由这个专用配置芯片把数据加载到FPGA中,然后FPGA就可以正常工作,由于配置时间很短,不会影响系统正常工作。 也有少数FPGA采用反熔丝或Flash工艺,对这种FPGA,就不需要外加专用的配置芯片。
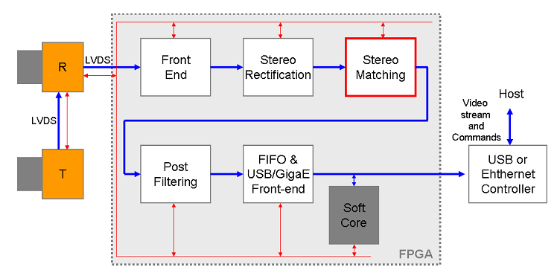
我们以双目算法为例,上图为一个典型的双目计算系统。双目最关键的就是匹配算法,通常有SAD、SSD、CENS等,其中最常见的是SAD。SAD(Sum of absolute differences)是一种图像匹配算法。基本思想:差的绝对值之和。此算法常用于图像块匹配,将每个像素对应数值之差的绝对值求和,据此评估两个图像块的相似度。该算法快速、但并不精确,通常用于多级处理的初步筛选。这种算法简单,但工作量大,非常适合FPGA。
基本流程,输入:两幅图像,一幅Left-Image,一幅Right-Image。对左图,依次扫描,选定一个锚点:
(1)构造一个小窗口,类似于卷积核;
(2)用窗口覆盖左边的图像,选择出窗口覆盖区域内的所有像素点;
(3)同样用窗口覆盖右边的图像并选择出覆盖区域的像素点;
(4)左边覆盖区域减去右边覆盖区域,并求出所有像素点灰度差的绝对值之和;
(5)移动右边图像的窗口,重复(3)-(4)的处理(这里有个搜索范围,超过这个范围跳出);
(6)找到这个范围内SAD值最小的窗口,即找到了左图锚点的最佳匹配的像素块。
以Altera的NIOS II为例,Altera提供SOPC builder这个工具,在里面嵌入NIOS II处理器和一些常用的IP 核。NIOS II处理器作为主机,其他外设作为从机,主机和从机之间通过AVALON MM总线进行通信与访问,每一个外设都有一个地址,NIOS II处理器可以通过这条总线对外设进行操作,但是每次只能访问一个外设。
系统硬件搭建好了之后,通过Quartus II对其进行综合,布局布线,时序约束等硬件系统搭建工作,然后我们用C语言通过NIOS II eclipse 这个工具来给硬件系统编程,并进行运行调试,最后将我们设计好的硬件与软件文件烧入FPGA的配置芯片或者FLASH中。
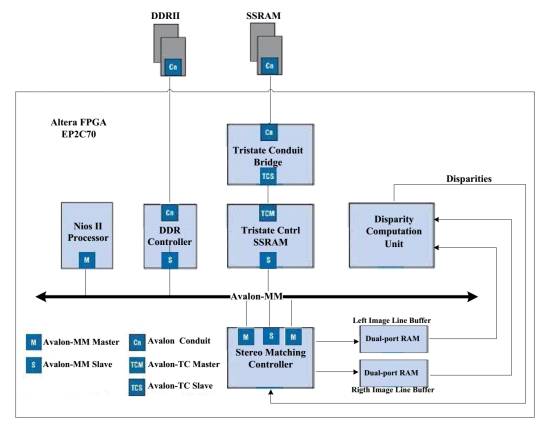
把CPU配置为双目匹配控制器,视差计算单元就是LB。
如果需要用到的算法多种多样且比较复杂,并且是计划用于消费类电子或汽车电子领域,那么FPGA是不合适的,FPGA在一定门数之上,性价比会很低,远低于ASIC。ASIC在价格、功耗、性能方面是全面超越FPGA的,FPGA应该说就是针对懒人的,它帮你实现任意组合,但是不做任何优化,而ASIC就是尽量优化,特别是物理层面的优化。比如你如果需要一个乘法器,ASIC可以保证乘法器离得非常近,连接线距离很短,延迟自然非常小,FPGA就没这能力。如果你需要大量的SRAM,多块不同位置的SRAM,你要如何满足timing需求?ASIC不同,ASIC里面可以保障你想要多大的SRAM就有多大的SRAM,而且可以做到物理布局得非常近,这样时钟就会很好。更不要说ASIC可以根据时钟需求更换cell。 FPGA的走线,你几乎是动不了的。ASIC中你可以直接加宽金属线,比如两倍宽度走时钟线,复位线之类的。金属线宽度变大,线上的延迟变小,对速度也是有帮助的。
当然啦,ASIC的前期成本太高,时间成本也很高,风险很高,有点像赌博,赌对了市场需求,就发财了,赌错了,直接破产。ASIC从立项到拿到芯片,一般在3-5年左右,一般生命周期最少也得3-5年,也就是说,立项的时候要准确把握5-6年后的市场需求,汽车电子日新月异,要想准确把握5-6年后的市场需求是很难的。
对于自动驾驶领域来说,深度学习芯片则是与传统芯片不同。因为深度学习是一类特定应用,深度学习特别是CNN图像识别的通用型芯片或许是可能的。
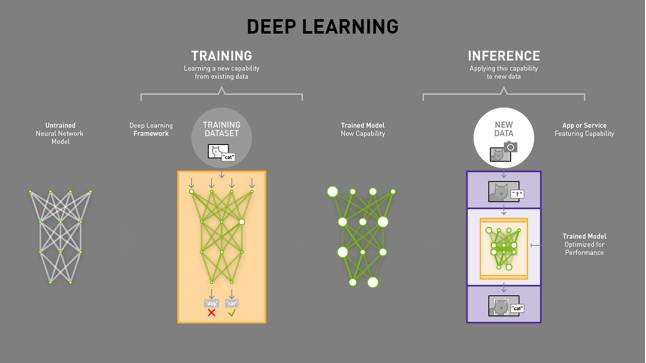
深度学习分训练和推理两部分,一般提到的深度学习芯片应该指推理部分的应用,训练端用CPU+GPU或CPU+FPGA,ASIC很难适应训练端的需求。谷歌的TPU也就是主打推理部分的应用,在自动驾驶领域,就是深度学习的嵌入式系统应用。
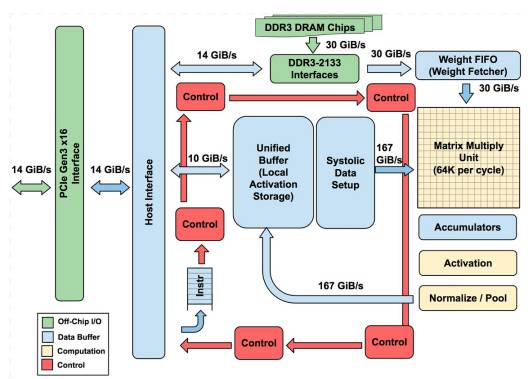
上图为谷歌的TPU架构图,TPU的架构看上去很简单,主要模块包括片上内存,256x256个矩阵乘法单元,非线性神经元计算单元(activation),以及用于归一化(Normalize)和池化的计算单元。
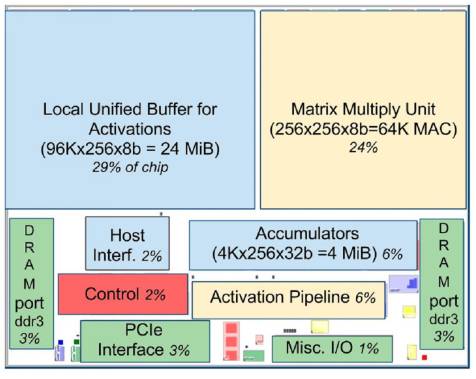
TPU在芯片上使用了高达24MB的局部内存,6MB的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的37%(图中蓝色部分)。这表示Google充分意识到片外内存访问是GPU能效比低的罪魁祸首,因此不惜成本在芯片上放了巨大的内存。相比之下,Nvidia同时期的K80只有8MB的片上内存,因此需要不断地去访问片外DRAM。256x256个矩阵乘法单元占芯片面积的30%,红色控制部分仅占2%,绿色输出输入部分占10%。
一般来说,ASIC的价格远低于FPGA或GPU,但是谷歌的TPU恐怕不是,它出货量显然远不及英伟达的GPU。GPU的出货量是其万倍以上,适用面很广,价格自然可以压低。芯片面积的37%都是内存,成本自然不低。
英特尔收购的Movidius就试图打造一款通用性比较强的可以用做深度学习嵌入式系统的芯片。
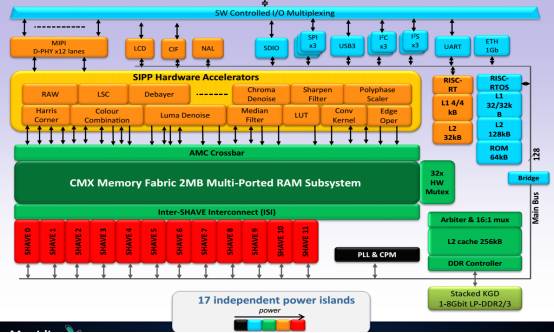
上图为Movidius Myraid2的内部框架图
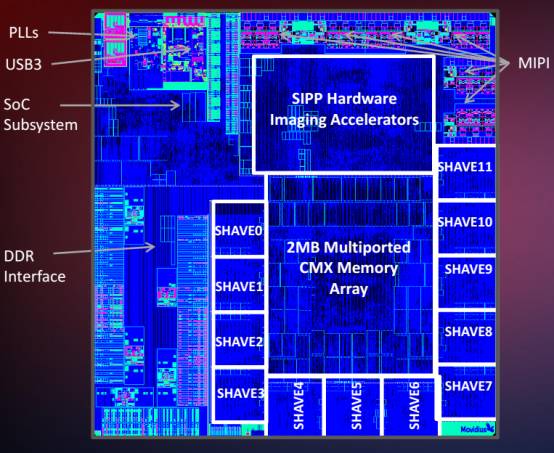
上图为Movidius Myraid2 die的电子显微镜图
Myraid2采用台积电28纳米HPC工艺制造,提供两种封装形式,一种为FC-BGA PoP封装,内含1Gbits LPDDR2内存。封装面积比较大有6.5*6.5毫米,0.4毫米间距。另一种封装形式,不含内存,采用WLCSP封装,封装面积5.1*5.3毫米,0.35毫米间距。

Myraid2的核心是5个SHAVE,SHAVE 包含宽而深的寄存器文件,加上一个提高代码大小效率的长指令集(VLIW),SIMD:单指令流多数据流(Single Instruction Multiple Data,缩写为SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据矢量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。其典型代表是向量处理器(Vector Processor)和阵列处理器(Array Processor)。比如有四个计算单元,给这个四个计算单元发一条加法指令,这样他们可以同时执行加法计算。向量计算x,y,z,w就是用到这个。
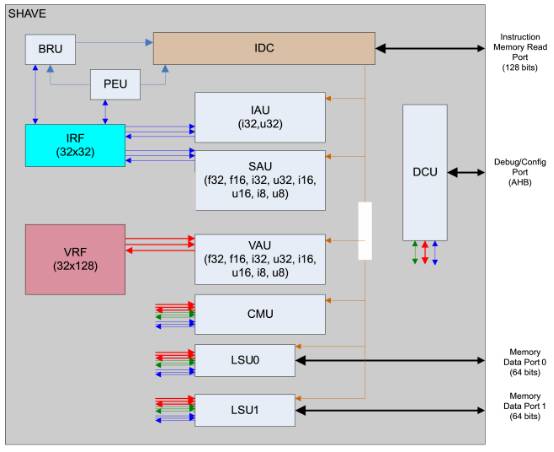
上图为Shave内部,IRF(整形寄存器文件),IRF包含32个寄存器,每个是32bit长。这些寄存器主要是实现对整形运算的支持,不仅如此,还用与加载和存取指令。执行和操作这些寄存器的是IAU(Integer Arithmetic Unit,整形运算单元)和 SAU(Scalar Arithmetic Unit标量运算单)。另外SIMD运算在SAU和IAU还有一些16bit和8bit的整数类型。
VRF(向量寄存器文件),VRF同样也包含32个寄存器,每个是128bit长度。 这些寄存器是为了给SHAVE提供SIMD操作。执行这些寄存器的称作VAU(Vector Arithmetic Unit)。 它同时支持整型和浮点运算,支持8,16, 32bit 整型或者浮点型。 SAU(Scalar Arithmetic Unit),这个单元为IRF提供浮点运算支持。除了最通用的浮点源运算,这个单元还实现一些复杂的16bit浮点运算,如:补运算,正弦, 平方根,平方根倒数,余弦,反正切,对数和指数。这个单元还为提供整型运算。假如有用,这个特点会更多的用来为IRF提供并行整型运算。CMU(Compare and Move Unit 比较移动单元),这个单元提供从一个寄存器拷贝数值到另外一个寄存器的功能。支持任意组合和多位长(bit)。这个单元也提供比较数据类型的功能。比较通过设定多种条件入口。 VRF也可以发起这个比较,比较多种数据。
LSU(Load Store Unit加载存储单元),有2个加载存储单元提供加载和存储数据给两个寄存器文件LSU和其他单元配合使用,混合操作多种数据类型,在SHAVE ISA文档上面有描述。BRU(Branching Unit分支单元),BRU提供分支功能。SHAVE 有一个5个周期的延时槽用来填写进其他的指令。
PEU(Predicate Execution Unit预测执行单元),PEU有助于实现条件分支预测和保存条件在LSU和 VAU单元里面。
大疆的无人机就采用这款芯片检测障碍物和避障。不过深度学习的本质是一个概率拟合的过程,同时又分为训练和推理两部分。训练需要海量的经过良好标注的数据,没有标注的数据,或者说没有人工准确标注的数据,训练的结果会大打折扣,标注需要高昂的成本,同时深度学习可能在某个测试集上表现很好,但是实际使用时又可能表现不好,要找出其中原因则非常困难。汽车工业可能难以接受这种典型的黑盒数学模型,同时它的成本也会因为数据标注的高昂成本而增加,尽管芯片本身不贵,可能外围的边际成本是芯片成本的十倍以上,这是阻碍深度学习嵌入式应用的另一个阻力。