2017年,激光雷达出尽风头,各种技术路线和初创企业让人眼花缭乱。11月8日,激光雷达头牌厂商Velodyne推出128线激光雷达VLS-128,其探测距离相较于其64线激光雷达提升一倍,而点云密度提高了四倍,体积却减少了70%。
刚过一个月的12月12日,在硅谷的华人初创企业Innovusion宣布推出300线激光雷达,在LIDAR探测清晰度和数据融合方面取得重大进展。
华人初创公司首发300线激光雷达
Innovusion公司CEO一直和佐思有密切的联系,我们也得知该团队在创业做传感器。Innovusion团队蛰伏一年后拿出的作品,着实让人惊讶。




据Innovusion CEO 鲍君威介绍,该款激光雷达为混合固态LIDAR,探测距离可大于150米,分辨率在300线以上,尺寸小于100⽴⽅英⼨(长度和普通智能手机相当)。高分辨率带来的益处是,可以对车辆前面的行人及障碍物返回更多扫描点,能够更准确识别人和物体。
某几十线LIDAR与Innovusion LIDAR的对比效果图

Innovusion激光雷达纵向分辨率达300线,可称为“图像级”的激光雷达。从2018年上半年开始Innovusion将启动开发者合作项目,可提供激光雷达B Sample以及integration kits,支持合作伙伴部署测试。该雷达量产时成本可降低至1000美元。
某32线LIDAR的扫描效果图

Innovusion LIDAR点云单帧数据图
(颜色代表反射值,场景为斯坦福校园)

Innovusion还实现了一项非常重要的功能,就是激光雷达点云与相机视频数据在硬件层次的融合,大大减少了传感器数据融合的软件处理时间。
融合前:摄像头彩色图像截图

融合后:三维彩色点云数据(激光雷达点云及摄像头数据融合视图)

融合后:三维彩色点云数据(上图拉近到远处的建筑物)

创始人曾就职于Velodyne和百度
Innovusion于2016年在美国硅⾕成立,公司团队多名成员是激光雷达及精密光学设备领域有丰富经验的⼯程师,平均业界工作经历近20年,一半以上成员有名校博士学位。
Innovusion CEO鲍君威本科毕业于北京大学物理系,在加州大学柏克莱分校获电子工程硕士及博士学位。在博士期间和两位师兄共同开发了可称之为“显微光学雷达”的Scatterometry 技术,创立Timbre Technologies, Inc.,在2001 年被Tokyo Electron 并购,并在随后的十几年里带领Tokyo Electron 在硅谷的光学测量部门将Scatterometry 从原理模型变成可实际应用的精密测量设备,引领了Scatterometry 技术及其它精密光学传感器在先进半导体生产制程中的广泛应用。
鲍君威在2014 年加入百度美国研发中心,负责开发大规模数据中心硬件加速及高性能网络。2015 年底加入百度自动驾驶事业部,负责车载计算系统及传感器团队, 集成自动驾驶系统所需的各类传感器,并建立团队来深度评测及调研各项新型传感器技术。
Innovusion CTO李义民在精密电子及测试仪器方面有二十多年的经验,2016 年11 月与鲍君威一起创立Innovusion。李义民在北京大学无线电系获得本科及博士学位,1999 年赴美在美国Argonne 国家实验室做博士后。随后在多家硅谷光通信及精密仪器公司开发技术,包括光纤激光器、超声波探测器、陀螺仪、电子显微镜及原子力显微镜等。
李义民2008 年至2011 年在Velodyne 作为工程团队核心成员研发激光雷达,2016 年初加入百度自动驾驶事业部,成为传感器团队技术负责人。
用激光雷达识别物体渐成趋势
苹果在上个月发表了一篇名为VoxelNet: End-to-End Learning for Point CloudBased 3D Object Detection;百度则在2016年发表了一篇Vehicle Detection from 3D Lidar Using Fully Convolutional Network;在更早的2015年,百度发表过一篇3D Fully Convolutional Networkfor Vehicle Detection in Point Cloud。2015年9月,卡梅隆大学机器人学院的Daniel Maturana 和Sebastian Scherer发表了VoxNet: A 3DConvolutional Neural Network for Real-Time Object Recognition。
2017年10月,德国弗赖堡大学机器视觉系发表了Orientation-boostedVoxel Nets for 3D Object Recognition。清华与百度还有一篇Multi-View3D Object Detection Network for Autonomous Driving。欧洲机器视觉权威瑞士苏黎世理工学院则有SEMANTIC3D.NET: A NEW LARGE-SCALE POINT CLOUD CLASSIFICATIONBENCHMARK。
这些论文都是对激光雷达物体识别的研究,激光雷达物体识别最大的优点是可以完全排除光线的干扰,无论白天还是黑夜,无论是树影斑驳的林荫道,还是光线急剧变化的隧道出口,都没有问题。其次,激光雷达可以轻易获得深度信息,而对摄像头系统来说这非常困难。第三,激光雷达的有效距离远在摄像头之上,更远的有效距离等于加大了安全冗余。最后,激光雷达也可以识别颜色和车道线。
实际上激光雷达与摄像头没有本质区别,其最大区别除了激光雷达是主动发射激光,是主动传感器外,只是光电接收二极管不同,摄像头可以做到的,激光雷达都能够做到,只是目前激光雷达的点云密集度还不能和300万像素级摄像头相比。本次Innovusion 300线激光雷达的发布,让激光雷达成为“高清晰度”LIDAR,使得激光雷达对物体的识别能力进入全新的阶段。
对于固态激光雷达来说,绝大部分固态激光雷达都是提供3D图像的,与其说是激光雷达,不如说是3D图像传感器更为合适。
清华与百度的Multi-View 3D Object Detection Network forAutonomous Driving(2016年11月),用摄像头和激光雷达数据融合做物体探测与识别,苹果认为这种做法没有提升,反而带来N多麻烦,因为摄像头需要时间同步和与激光雷达做联合空间标定,摄像头有效距离有限,性能与距离关联密切。两者在中远距离上难以融合,在近距离效果会略好。
像摄像头用像素Pixel这个词一样,激光雷达是3D的,因此有Voxel体素这个词。Pixel是二维电脑图像的最小单位,Voxel则是三维数据在三维空间分割上的最小单位,很早就应用于三维成像、医学影像(比如CT)等领域。对物体识别是机器理解人类社会环境的基本能力,人类文明主要是用文字和语言承载的,这是一种完全社会化的概念,因此不得不采用人类的学习方式,也就是深度学习。激光雷达可以用回波宽度或反射强度信息轻易识别某一类物体,如车道线,草地,建筑物,道路,树木,并且是物理识别,而不是摄像头那样的根据数学概率算法得出的识别,物理识别的准确度远高于概率推算。
但是需要更具体识别的话,激光雷达只能识别出是行人,但到底是成年人、老人、小孩还是婴儿就无能为力了。再比如路边的交通标识,激光雷达只能知道是一块金属牌或塑料牌,但是是牌子什么内容就不知道了,深度学习就可以派上用场了。
深度学习通俗的理解就像人类训练动物,比如教你们家汪星人跟你握手(爪),汪星人做对了,就给一点食物奖励或者抚摸奖励,这就是一种强化学习的机制,汪星人没做对,就会挨批。这就像神经网络的训练过程,识别正确就增加这部分的权重值(食物奖励),识别错误就减少权重值(挨批)。如此不断地强化,最终你一伸手,汪星人也伸爪跟你握手。
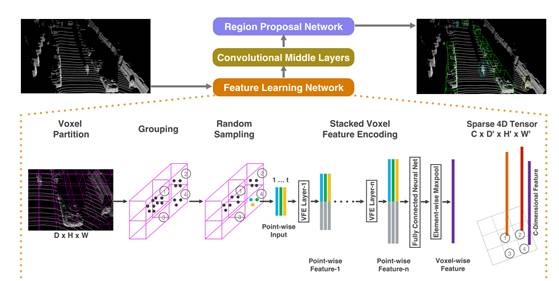
上图为苹果论文里的Voxel Net架构。目标检测与识别领域早期为DPM。2013年11月,目标检测领域公认的大神RossGirshick推出R-CNN,2015年4月进化为Fast R-CNN,2015年6月进化为Faster R-CNN,成为今日目标检测与识别领域公认最好的方法,也是可以完全端对端地实现。激光雷达的目标检测与识别自然也是要用Faster R-CNN。
Faster R-CNN 从2015年底至今已经有接近两年了,但依旧还是Object Detection领域的主流框架之一,虽然推出了后续 R-FCN,Mask R-CNN 等改进框架,但基本结构变化不大。同时不乏有SSD,YOLO等骨骼清奇的新作,但精度上依然以Faster R-CNN为最好。
从RCNN到fastRCNN,再到本文的faster RCNN,目标检测的四个基本步骤(候选区域生成、特征提取、分类、位置精修)终于被统一到一个深度网络框架之内。所有计算没有重复,完全在GPU中完成,大大提高了运行速度。
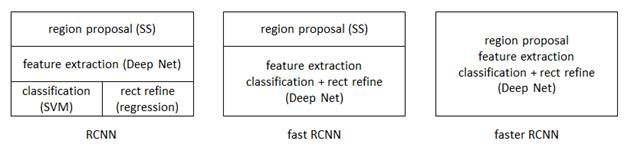
faster RCNN可以简单地看做“区域生成网络+fast RCNN“的系统,用区域生成网络RPN(Region Proposal Networks)代替fast RCNN中的Selective Search方法。不过RPN只能针对密集化的具备张量结构的数据,而激光雷达的云点是稀疏的,因此激光雷达深度学习识别物体的关键就是如何把点云数据转换成具备张量结构的密集的视频或图像数据。
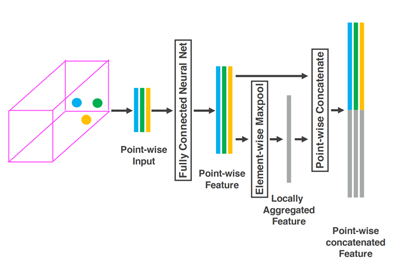
苹果就提出了一种叫VFE(Voxel FeatureEncoding)的方案,如上图所示。首先将点云数据转换为体素数据,基本上点云的三维数据就是体素的三维数据。根据体素所在的位置对点(点云)进行分组,把这些分组数据全部一层层堆叠起来,然后通过FCN形成有4(速度向量、X、Y、Z)张量的数据结构。所谓的VFE,感觉类似于CNN的卷积。既然是CNN,就少不了池化,苹果叫随机取样,就是下取样。
接下来看FCN,FCN将传统CNN中的全连接层转化成卷积层,对应CNN网络FCN把最后三层全连接层转换成为三层卷积层。在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个不同类别的概率。FCN将这3层表示为卷积层,卷积核的大小 (通道数,宽,高) 分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。看上去数字上并没有什么差别,但是卷积跟全连接是不一样的概念和计算过程,使用的是之前CNN已经训练好的权值和偏置,但是不一样的在于权值和偏置是有自己的范围,属于自己的一个卷积核。因此FCN网络中所有的层都是卷积层,故称为全卷积网络。
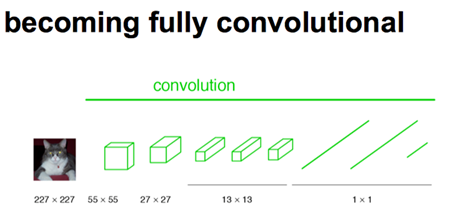
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特征图。
得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。这就可以看做RPN了。
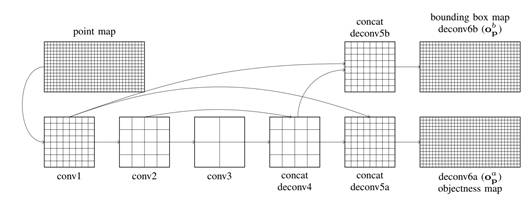
上图是百度的云点转换FCN步骤图。
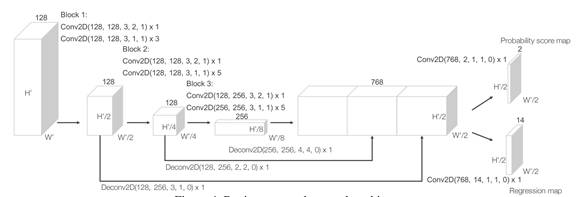
上图为苹果的RPN架构图。可以看出与百度相差无几。
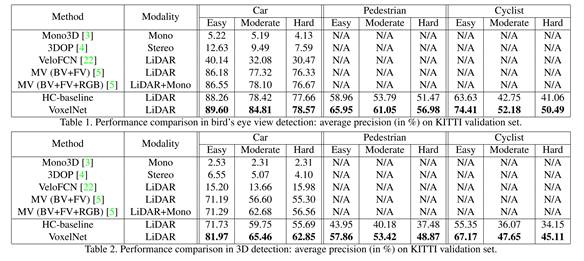
最后不能免俗,苹果也得上KITTI上测试一番,苹果也忘不了打击一下百度,其中22号方案是百度早期的方案,效果确实不太好;5号方案就是百度和清华合作的方案,BV代表鸟瞰图,FV代表前视图,RGB代表摄像头。HC-baseline的方案也是清华和百度联合提出的。在鸟瞰检测方面,苹果与百度几乎没太多差别,在3D检测方面,苹果领先不少。
苹果使用一个1.7GHz的CPU和顶级显卡Titan X来运行上述算法,Voxel输入特征计算费时大约5毫秒,特征学习网络费时大约20毫秒,卷积中间层费时170毫秒,RPN网络费时30毫秒,合计225毫秒,但是苹果没有说这是一帧的推理(Inference)时间还是30帧,如果是一帧的话那就离实用还差很远,每帧25毫秒还比较接近实用。
这也说明,实现完全自动驾驶还有一大段路要走。无论是激光雷达,还是视觉技术,都还有很大的提升空间。 本文截稿之前,得知激光雷达企业Ouster刚完成2700万美元A轮融资,可见LIDAR市场之热度。据悉,Innovusion现在也启动了A轮融资。