目前集成电路设计基本上都是用IP核搭积木的形式。IP核分为行为(Behavior)、结构(Structure)和物理(Physical)三级不同程度的设计,对应描述功能行为的不同分为三类,即软核(Soft IP Core)、完成结构描述的固核(Firm IP Core)和基于物理描述并经过工艺验证的硬核(Hard IP Core)。软核就是我们熟悉的RTL代码;固核就是指网表;而硬核就是指指经过验证的设计版图。ARM还是以软核为主的。
IP软核(Soft IP Core):通常是用硬件描述语言(hardware Description Language,HDL)文本形式提交给用户,它经过RTL级设计优化和功能验证,但其中不含有任何具体的物理信息。据此,用户可以综合出正确的门电路级设计网表,并可以进行后续的结构设计,具有很大的灵活性。借助于EDA综合工具可以很容易地与其他外部逻辑电路合成一体,根据各种不同半导体工艺,设计成具有不同性能的器件。其主要缺点是缺乏对时序、面积和功耗的预见性。而且IP软核以源代码的形式提供的,IP知识产权不易保护。
IP硬核(Hard IP Core)是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件。由于无需提供寄存器转移级(Register transfer level,RTL)文件,因而更易于实现IP保护。其缺点是灵活性和可移植性差。IP固核(Firm IP Core)的设计程度则是介于软核和硬核之间,除了完成软核所的设计外,还完成了门级电路综合和时序仿真等设计环节。一般以门级电路网表的形式提供给用户。
目前由于算法变化迅速,因此大部分算法都以软核的形式出现,在ARM这类纯RISC处理器上,就表现出很低的效率,因为汽车领域的算法与手机领域完全不同,需要强大的译码器,而ARM处理器的译码器不能胜任,人脸识别之类的视觉算法,30帧的处理时间有些长达1秒。X86架构就会好一些,当然最好还是硬核,和译码器无关,完全物理结构,例如日系的大部分视觉处理器。硬核的代价也高,芯片的研发周期长且需要更多的研发人员,研发过程中一次出错就可能错过上市时间,风险很高。其次是成本高,芯片的面积更大。但性能是通用处理器的20倍甚至50倍以上。
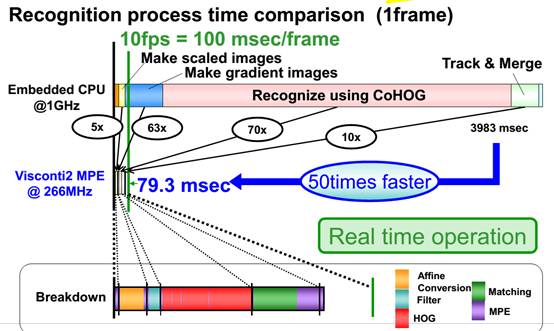
上图是一个典型的行人识别算法HOG+SVM所需要时间的对比,硬核只需要79.3毫秒,软核需要3983毫秒,所以纯软核的设计要么用极简单的算法,要么用英伟达贵到飞起的芯片。所以单纯的算法公司,特别是复杂视觉处理算法公司如果不能将算法用芯片来承载,那就不可能成功。如果你害怕硬核的风险、长研发周期和高成本,在硬核和软核之间还有固核选择,固核更接近硬核,但依然必须有芯片承载。这就是Mobileye。
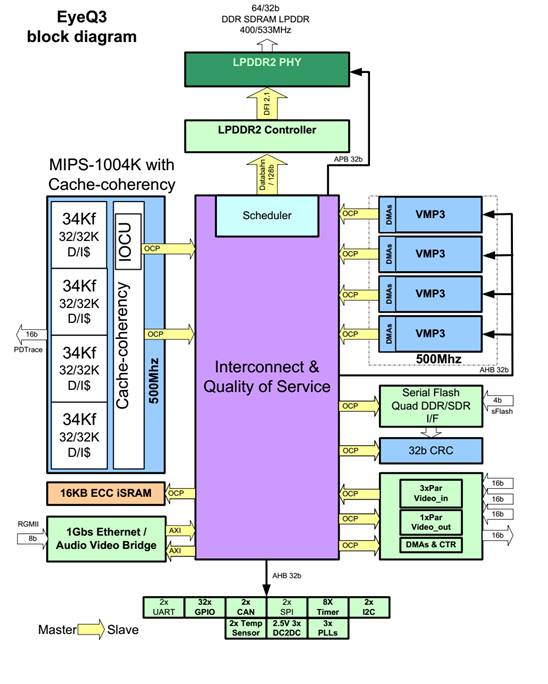
上图为Mobileye EYEQ3的内部框架图。EyeQ3使用了四个多线程MIPS32内核和四个矢量微码处理器(VMP)内核,在一个专门为处理视频设计的架构内工作。
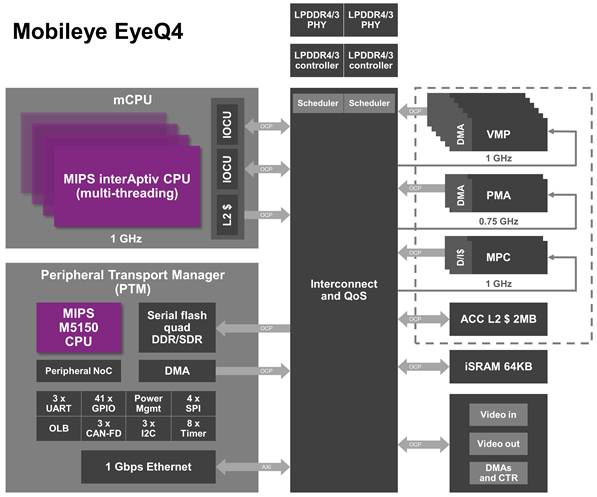
上图为EYEQ4的内部框架图,EYEQ5也与这个相差无几。实际Mobileye的核心一直未变,就是VMP,Mobileye只是简单地增加VMP的数量和提升VMP的运行频率。MIPS并不是其核心,MIPS只是做MCU,控制外围单元。
VMP才是运算核心,而VMP的核心是VLIW和SIMD。SIMD =single instruct more data 即单指令多数据,是CPU或GPU常用的一种结构,简单说就是一个控制端,多个执行端( 与此对应的是nvidia的MIMD架构),一条指令包含多个操作数据。VLIW 能使内核传送高级指令,同时 SIMD 允许单指令在多数据环境中运作,使每条指令都能完成更多的任务,收到一举多得、事半功倍的效果,两者配合效率惊人。
VLIW还有个优势就是设计人员能用 C 和 C++ 之类的高级语言编写应用程序,大幅降低开发成本,显著缩短产品上市时间。第一个此类产品是ATI的DX10,诞生于2006年,然而市场不买账,最终ATI被AMD收购后销声匿迹。ATI与意法半导体交好,AMD收购ATI后,芯片由意法半导体代工,而Mobileye当年恰巧找意法半导体设计芯片将其算法固化,意法半导体立刻想到了VLIW和SIMD。
不过和日本芯片公司如东芝或富士通的硬核相比,Mobileye的固核仍然稍逊一筹。但日本人圈子太小,成本略高,服务太差,始终无法推广,Mobileye才得以一飞冲天。技术上Mobileye仍然是上世纪80年代的VLIW,跟英伟达的丹佛一样,差别不大。
英伟达在2011年的CES上宣布丹佛计划,就是一种全新的CPU架构。2011年12月,第一片丹佛架构处理器流片成功。丹佛架构就是采用ARM V8的指令集,但是架构是沿用Transmeta全美达的VLIW架构,全美达在2000年发起对巨人英特尔的挑战,2004年挑战失败退出CPU领域,2008年英伟达延揽了全美达的核心技术人员,开始开发丹佛架构。不过当时定位的是PC用。
VLIW是美国Multiflow和Cydrome公司于20世纪80年代设计的体系结构,主要应用于全美达公司的Crusoe和Efficeon系列处理器中。
VLIW体系结构采用多个独立的功能部件,每一个指令周期在没有相关存在并符合硬件条件的情况下可以同时流出多条指令,可同时流出的操作类型与数目是确定的,所以指令调度是由编译器静态调度完成(在其它方法中均由硬件实现的)以减少硬件开销,因此指令可同时流出的最大数目越大,超长指令字的性能优势就越明显。但是,只要是并行处理,就一定会受到更多相关性的限制。这种相关是有程序本身造成的,分为控制相关和数据相关两种,指令在调度时,必须遵循它们之间的依赖关系,防止冲突发生。每时钟周期例如VLIW可运行20条指令,而CISC通常只能运行1-3条指令,RISC能运行4条指令,可见VLIW要比CISC和RISC强大的多。
VLIW优点:简化了处理器的结构,删除了处理器内部许多复杂的控制电路,这些电路通常是超标量芯片(CISC和RISC)协调并行工作时必须使用的,VLIW的结构简单,也能够使其芯片制造成本降低,价格低廉,能耗少,而且性能也要比超标量芯片高得多。VLIW是简化处理器的最新途径,VLIW芯片无需超标量芯片在运行时间协调并行执行时所必须使用的许多复杂的控制电路。而是将许多这类负担交给了编译器去承担。
VLIW缺点:基于VLIW指令集字的CPU芯片使得程序变得很大,需要更多的内存,也就意味着更高的成本。更重要的是编译器必须更聪明,一个低劣的VLIW编译器对性能造成的负面影响远比一个低劣的RISC或CISC编译器造成的影响要大。当年全美达就输在指令集上,对第三方软件支持度很差。而英伟达吸取了这个教训,改用ARM的指令集。
2014年NVIDIA推出Tegra K1,采用双核丹佛架构的CPU,据geekbench测试采用了该芯片的谷歌平板nexus9其单核性能高达1903分,比当时苹果A8的1625分还要高17%,而高通的骁龙805的单核性能只有1112。TegraK1和骁龙805都是采用28nm工艺,苹果的A8处理器采用的是20nm工艺,在工艺落后的情况下K1的丹佛核心能有如此惊人的性能无疑是让人惊讶的。ARM开发的公版核心直到去年推出的A72采用16nmFF+工艺的情况下可以达到这一水平,可见NVIDIA丹佛架构CPU方面的强大实力。

上图为当年的TEGRA K1,一个芯片,两个版本,也让我们可以对比丹佛和ARM大的不同,图中很明显,丹佛架构的CPU所占硅片面积更大,几乎是A15的两倍。基本上成本也是A15的两倍,1级缓存也要多4倍,成本还得增加不少。不过没有ARM的专利费,可以略微降低点成本。
上图是当年丹佛的定位,就是做PC和服务器的。不过,显然失败了。
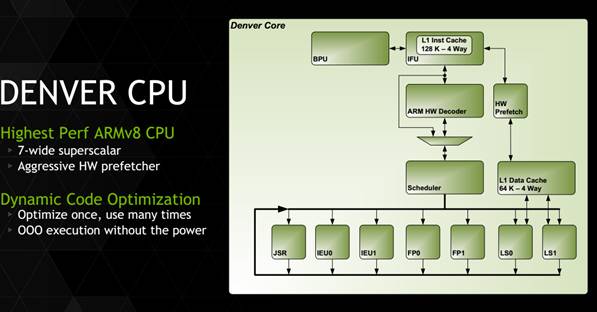
上图为丹佛架构。
2016年下半年,苹果A10处理器又将移动SoC的性能推向了另一个高峰,而Denver却一直没有消息,随后的Tegra X1也是采用的ARM的Cortex-A57核心。Denver以及其后续产品的发展,一直是业内关注的重点。要知道,英伟达之前研发Denver耗费了五年时间、数百名顶级工程师,这样庞大的遗产不可能说没就没。于是在2016年8月,英伟达推出第二代基于丹佛架构的CPU,就是Tegra Parker,目标瞄准汽车市场。
和之前的Tegra X1、Tegra K1 A15版本完全不同的是,在Tegra Parker拥有6个CPU核心,且英伟达自有的Denver系列架构又出现了,还升级到了Denver 2。宏观上来看,Tegra Parker的CPU部分有两个簇,其中一个簇中包含了2颗Denver 2架构的CPU核心,另一个簇中包含了4颗Cortex-A57架构的核心,两个簇之间通过缓存后再使用HMP总线互联并保证缓存一致性。
在缓存方面,Tegra Parker的2个Denver2核心和4个Cortex-A57核心分别配备了2MB的L2缓存,然后双方的L2缓存再通过一致性单元连接在一起。L1缓存方面有点复杂,Denver 2和之前的Denver一样,使用了128KB指令缓存搭配64KB数据缓存;而Cortex-A57则是48KB指令缓存搭配32KB数据缓存,从缓存容量的差别上就能看出双方架构设计存在巨大差异。内存方面则支持LPDDR4内存,带宽为50GB/s,支持ECC校验,相比上代产品大幅度提升。
英伟达几乎没有给出任何有关Denver 2架构的信息,也没有说明新的架构在何处进行了升级。只是简略提到了Denver 2依旧是7-way的超标量架构、支持乱系执行、每瓦特性能非常优秀、支持低功耗模式等。有关Denver 2的内容,还需要等待随后更多资料流出才能明确。这次Tegra Parker的CPU部分采用的是“2+4”的模式,一般来说,如果采用ARM的big.LITTLE架构的话,应该是“高性能核心+节能核心”的模式,但是Tegra Parker却是“Big+Super”也就是“高性能核心+超高性能核心”的模式,这样一来,Tegra Parker面向的市场基本就放弃了手机,缺乏节能核心的它不太适合在小尺寸设备内存在,甚至平板上使用Tegra Parker可能也会存在散热问题。不过,Tegra Parker面向的市场应该就是车载和大尺寸设备,并不用太担心功耗问题,这样的搭配反而能取得最好的性能。
另外,Tegra Parker中还有一些问题需要考虑:比如为什么使用两颗Denver 2搭配四颗Cortex-A57而不是四颗(甚至六颗)Denver2?为什么不是六核心Cortex-A57(或者Cortex-A72)?对此英伟达做出了一些解释。最好的理由是自动驾驶需要更强大的单核心性能,而非多核心性能。因为汽车处理器的任务都是单线程居多。
至于下一代的XAVIER,目前未公布太多资料,仅知道是8核,可能是两颗Denver 3搭配6核A57。