Data closed loop research: as intelligent driving evolves from data-driven to cognition-driven, what changes are needed for data loop?
As software 2.0 and end-to-end technology are introduced into autonomous driving, the intelligent driving development model has evolved from the rule-based sub-task module to the data-driven stage AI 2.0, and is gradually developing towards artificial general intelligence (AGI), namely, AI 3.0.

At the Auto China 2024, SenseAuto showcased its next-generation autonomous driving technology: preview of DriveAGI, which is based on large multimodal models for improvement and upgrade of end-to-end intelligent driving solutions. DriveAGI is the evolution of autonomous driving foundation models from data-driven to cognition-driven, beyond the concept of driver, deepening understanding of the world, and boasting greater reasoning, decision and interaction capabilities. In autonomous driving, it is currently the technical solution that is closest to human thinking patterns, can understand human intentions best, and has the strongest ability to cope with difficult driving scenarios.

Data closed loop is indispensable to autonomous driving R&D after AI 1.0, but at different stages of AI application in autonomous driving, the requirements for each link of data closed loop vary greatly.
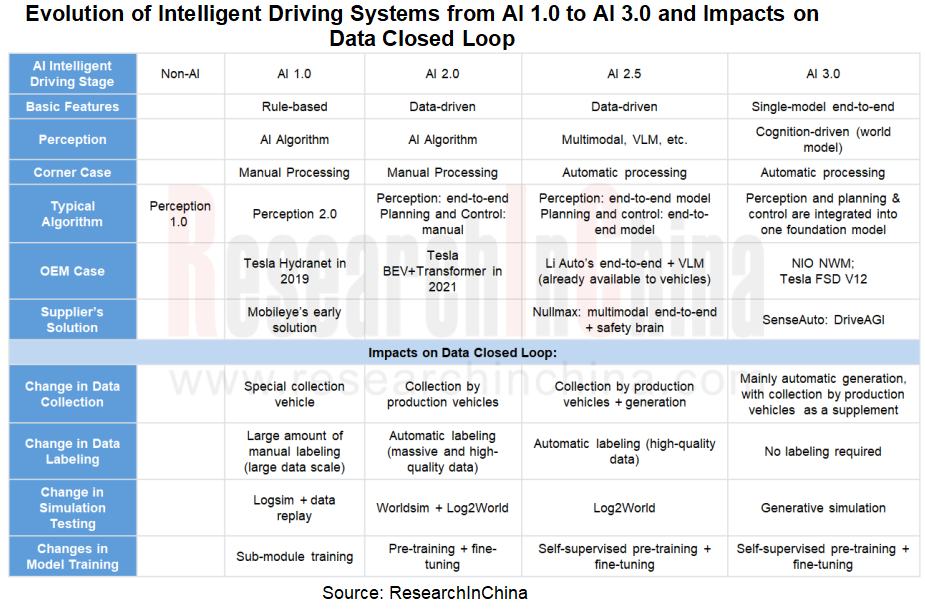
What changes will the full-stack model development of intelligent driving systems bring to the data closed loop?
1. The data collection mode has shifted from large-scale collection by collection vehicles to long-tail scenario collection by production vehicles, with more emphasis on high-quality data.
From the perspective of data flow, there are currently many ways to collect intelligent driving data, including collection by special collection vehicles, data collection and backhaul by production vehicles, roadside data collection and fusion, traffic data collection by drones at low altitudes, and simulated synthetic data, in a bid to achieve the maximum coverage, the most generalized scenarios, and the most complete data types, and ultimately fulfill the three elements of data: mass, completeness, and accuracy. Wherein, data collection by production vehicles is the mainstream mode.

As can be seen from the above table, OEMs keep accumulating massive amounts of intelligent driving data with production vehicles, and extracting effective and high-quality data to train AI algorithms. For example, Li Auto has scored the driving behaviors of more than 800,000 car owners, about 3% of which are scored above 90 and can be called "experienced drivers." The driving data of the experienced drivers of fleets is the fuel for training end-to-end models. It is estimated that by the end of 2024, Li Auto's end-to-end model is expected to learn over 5 million kilometers.
So, with sufficient enough data, how can we fully extract effective scene data and mine higher-quality training data? You can get to know from the following examples:
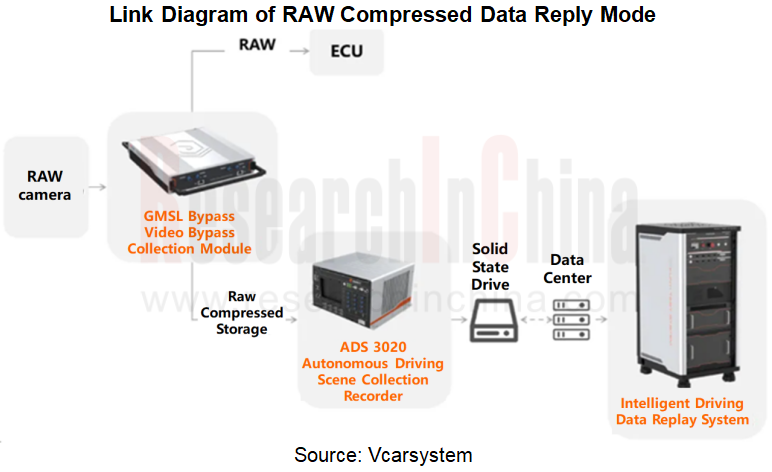
In terms of data compression, the data collected by vehicles often comes from the environmental perception data of vehicle systems and various sensors. Before being used for analysis or model training, the data must be preprocessed and cleaned strictly to ensure its quality and consistency. The vehicle data may come from different sensors and devices, and each device may have its own specific data format. High-definition intelligent driving scene data stored in RAW format (i.e., raw camera data that has not been processed by the ISP algorithm) will become a trend of high-quality scene data in the future. In Vcarsystem’s case, its "camera-based RAW data compression and collection solution" not only improves the efficiency of data collection, but also maximizes the integrity of the raw data, providing a reliable foundation for subsequent data processing and analysis. Compared with the traditional ISP post- compressed data replay, RAW compressed data replay avoids the information loss in the ISP processing process, and can restore the raw image data more accurately, improving the accuracy of algorithm training and the performance of the intelligent driving system.
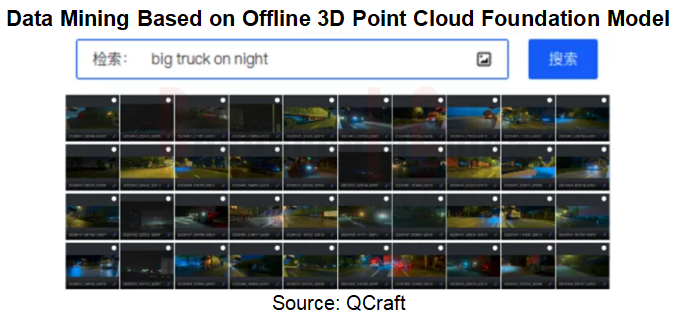
As for data mining, data mining cases based on offline 3D point cloud foundation models deserve attention. For example, based on offline point cloud foundation models, QCraft can mine high-quality 3D data and continuously improve object recognition capabilities. Not only that, QCraft has also built an innovative multimodal model based on text to image. Just with natural language text descriptions, the model can automatically retrieve corresponding scene images without supervision and mine many long-tail scenes that are difficult to find in ordinary data use and hard to encounter in life, thereby improving the efficiency of mining long-tail scenes. For example, as text descriptions such as "a large truck traveling in the rain at night" and "people lying at the roadside" are inputted, the system can automatically give a feedback on the corresponding scene, favoring special analysis and training.
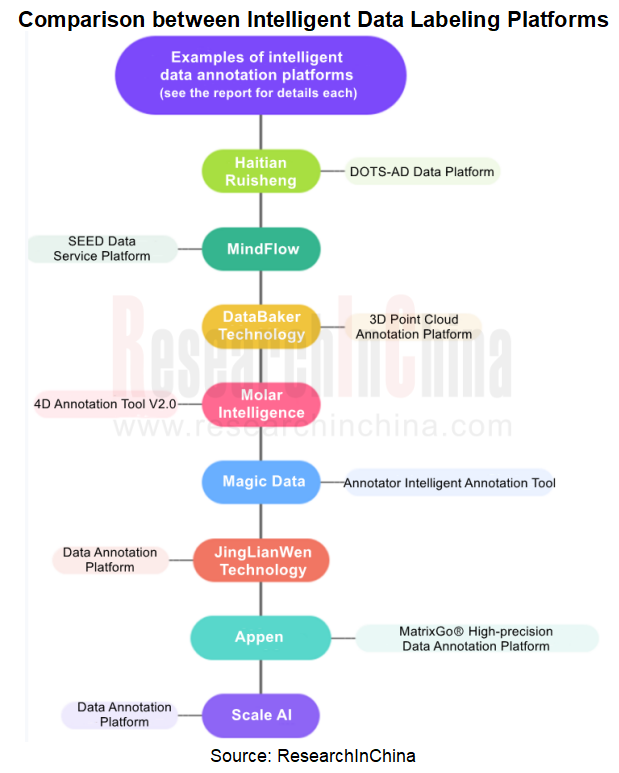
2. Data labeling is heading in the direction of AI-automated high-precision labeling, and will tend to be used less or no longer needed in the future.
As foundation models find broad application and deep learning technology advances, the demand for data labeling makes explosive growth. The performance of foundation models depends heavily on the quality of input data. So the requirements for the accuracy, consistency, and reliability of data labeling become increasingly higher. To meet the high demand for data labeling, many data labeling companies have begun to develop automatic labeling functions to further improve data labeling efficiency. Examples include:
Based on the automation capabilities of foundation models, DataBaker Technology has launched 4D-BEV, a new labeling tool which supports the processing of hundreds of millions of pixel point clouds. It helps to quickly and accurately perceive and understand the surroundings of the vehicle, and combines static and dynamic perception tasks for multi-perspective, multi-sequential labeling of objects such as vehicles, pedestrians and road signs, providing more accurate information like object location, speed, posture and behavior. It can also provide interactive information of different objects in the scene, helping the autonomous driving system to better understand the traffic conditions on the road, so as to make more accurate decisions and control. To improve the efficiency and accuracy of labeling, DataBaker Technology adds machine vision algorithms to 4D-BEV to automatically complete complex labeling work, enabling high-quality recognition of lane lines, curbs, stop lines, etc.
MindFlow’s SEED data labeling platform supports all types of 2D, 3D, and 4D labeling in autonomous driving and other scenarios, including 2/3D fusion, 3D point cloud segmentation, point cloud sequential frame overlay, BEV, 4D point cloud lane lines and 4D point cloud segmentation, and covers all labeling sub-scenarios of autonomous driving. In addition, its AI algorithm labeling model incorporates AI intelligent segmentation based on the SAM segmentation model, static road adaptive segmentation, dynamic obstacle AI preprocessing, and AI interactive labeling. It improves the average efficiency of data labeling in typical autonomous driving scenarios by more than 4-5 times, and by more than 10-20 times in some scenarios. In addition, MindFlow’s data labeling foundation model is based on weak supervision and semi-supervised learning, and uses a small amount of manually labeled data and a mass of unlabeled data for efficient detection, segmentation, and recognition of scene objects.
Additionally, on July 27, 2024, NIO officially announced NWM (NIO World Model), China's first intelligent driving world model. As a multivariate autoregressive generative model, it can fully understand information, generate new scenes, and predict what may happen in the future. It is worth noting that as a generative model, NWM can use a 3-second driving video as Prompt to generate a 120-second video. Through the self-supervision process, NWM can need no data labeling and becomes more efficient.
3. Simulation testing is becoming increasingly important in development of intelligent driving. High accuracy and high restoration capabilities are the key to improving the quality of scene coverage.
High-level intelligent driving needs to be tested in various complex and diverse scenarios, which requires not only high precision sensor perception and restoration capabilities, but also powerful 3D scene reconstruction capabilities and scene coverage generalization capabilities.
PilotD Automotive’s full physical-level sensor model can simulate detailed physical phenomena, for example, multi-path reflection, refraction, interference and multi-path reflection of electromagnetic waves, or dynamic sensor performance such as detection loss rate, object resolution and measurement inaccuracy, and "ghost" physical phenomena, so as to obtain high fidelity required by the sensor model. The full physical-level sensor model based on PilotD Automotive’s PlenRay physical ray technology currently boasts a simulation restoration rate of over 95%.
dSPACE's AURELION (high-precision simulation of 3D scenes and physical sensors) is a flexible sensor simulation and visualization software solution. Based on physical rendering by a game engine, it simulates pixel-level raw data of camera sensors. AURELION's radar module uses ray tracing technology to simulate the signal-level raw data of ray-type sensors. Considering the impacts of specific materials on LiDAR, the output point cloud contains reflectivity values close to real calculations. For each ray, it provides realistic motion distortion effects and configurable time offset values.
RisenLighten’s Qianxing Simulation Platform adds rich and realistic pedestrian models, and supports customization of micro trajectories of pedestrians and batch generation of pedestrians. Moreover, the platform also provides different high-fidelity pedestrian behavior style models, covering such scenarios as human-vehicle interaction, crossing, and diagonal crossing at intersections. It models three types of drivers (conservative, conventional and aggressive), and refines parameters by probability distribution, so as to diversify and randomize driving behaviors of vehicles in the environment.
As a generative simulation model, NIO NSim can compare each trajectory deduced by NWM with the corresponding simulation results. Originally they could only be compared with the only trajectory in the real world. Yet adding NSim enables joint verification in tens of millions of worlds, providing more data for NWM training. This makes the output intelligent driving trajectory and experience safer, more reasonable, and more efficient.
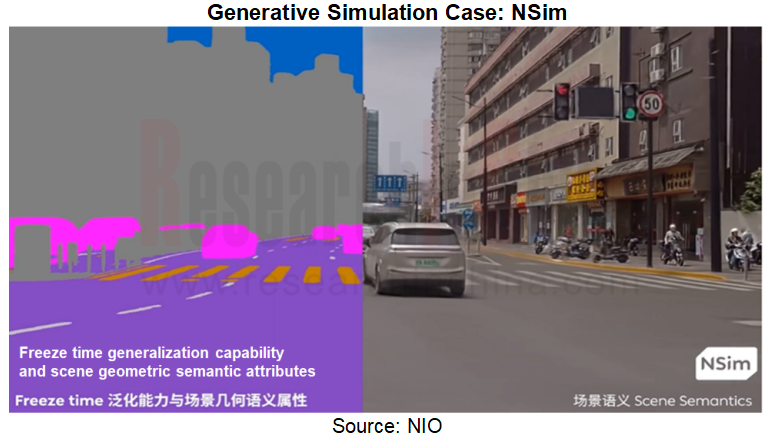
In the field of autonomous driving, end-to-end solutions have a more urgent need of high-fidelity scenes. For the end-to-end system needs to cope with various complex scenarios, a lot of videos labeled with autonomous driving behaviors need to be put into autonomous driving training. With regard to 3D scene reconstruction, currently penetration and application of 3D Gaussian Splattering (3DGS) technology in the automotive industry accelerate. This is because 3DGS performs well in rendering speed, image quality, positioning accuracy, etc., fully making up for the shortcomings of NeRF. Meanwhile the reconstructed scene based on 3DGS can replicate the edge scenes (Corner Case) found in real intelligent driving. By dynamic scene generalization, it improves the ability of the end-to-end intelligent driving system to cope with corner cases. Examples include:
51Sim innovatively integrates 3DGS into traditional graphics rendering engines through AI algorithms, making breakthroughs in realism. 51Sim fusion solution has high-quality and real-time rendering capabilities. The high-fidelity simulation scene not only improves the training quality for the autonomous driving system, but also significantly improves the authenticity of simulation, making it almost indistinguishable to naked eyes, greatly improving the confidence of simulation, and making up for shortfalls of 3DGS in details and generalization capabilities.
In addition, Li Auto also uses 3DGS for simulation scene reconstruction. Li Auto's intelligent driving solution consists of three systems, namely, end-to-end (fast system) + VLM (slow system) + world model. Wherein, the world model combines two technology paths: reconstruction and generation. It uses 3DGS technology to reconstruct the real data, and the generative model to offer new views. In scene reconstruction, the dynamic and static elements are separated, the static environment is reconstructed, and the dynamic objects are reconstructed and a new view is generated. After re-rendering the scene, a 3D physical world is formed, in which the dynamic assets can be edited and adjusted arbitrarily for partial generalization of the scene. The generative model features greater generalization ability, and allows weather, lighting, traffic flow and other conditions to be customized to generate new scenes that conform to real laws, which are used to evaluate the adaptability of the autonomous driving system in various conditions.


In short, the scene constructed by combining reconstruction and generation creates a better virtual environment for learning and testing the capabilities of the autonomous driving system, enabling the system to have efficient closed-loop iteration capabilities and ensuring the safety and reliability of the system.
4. The rapid development of OEMs’ full-stack self-development capabilities prompts data closed-loop technology providers to keep improving their service capabilities.
The data closed loop is divided into the perception layer and the planning and control layer, both of which have an independent closed loop process. In both aspects, data closed loop technology providers have the ability to improve their service capabilities, for example:
In terms of perception, in the project development process, the version of the autonomous driving system will be released regularly, integrating and packaging all the contents such as perception, planning and control, communication, and middleware. Some intelligent driving solution providers such as Nullmax will release the perception part separately first, and then test it through automatic tools and testers, output specific reports, and evaluate the fixing of the problems at the early stage. If there are problems with the perception version, there is still time to continue to modify and test it. This can greatly avoid the upstream perception problems from affecting the entire system, and is more conducive to problem location and system improvement, greatly improving the efficiency of system release and project development.
In terms of planning and control, in QCraft’s case, its self-developed “joint spatio-temporal planning algorithm” takes into account both space and time to plan the trajectory, and solves the driving path and speed in three dimensions simultaneously, rather than solve the path separately first and then solve the speed based on the path to form the trajectory. Upgrading "horizontal and vertical separation" to "horizontal and vertical combination" means that both path and speed curves will be used as variables in the optimization problem to obtain the optimal combination of the two.
Data closed-loop technology providers generally provide complete data closed-loop solutions or separate data closed-loop products (i.e. modular tool services, e.g., annotation platform, replay tool and simulation tool) for OEMs and Tier1s. OEMs with great data governance capabilities often outsource tool modules that they are not good at, and integrate them into their own data processing platform systems; while OEMs with weak data governance capabilities will consider tightly coupled data closed-loop products or customized services, for example, FUGA, Freetech’s new-generation tightly coupled data closed-loop platform product, has gathered more than 8 million kilometers of real mass production data, and experience in algorithm closed-loop iteration of over 100 production models, achieving more than 100-fold algorithm iteration efficiency and managing over 3,000 sets of high-value scene data fragments per month. At present, FUGA has been deployed and applied in production vehicle projects of multiple leading OEMs, supporting daily test data problem analysis, and weekly data cleaning and statistical report analysis.
Autonomous Driving Domain Controller and Central Computing Unit (CCU) Industry Report, 2025
Research on Autonomous Driving Domain Controllers: Monthly Penetration Rate Exceeded 30% for the First Time, and 700T+ Ultrahigh-compute Domain Controller Products Are Rapidly Installed in Vehicles
L...
China Automotive Lighting and Ambient Lighting System Research Report, 2025
Automotive Lighting System Research: In 2025H1, Autonomous Driving System (ADS) Marker Lamps Saw an 11-Fold Year-on-Year Growth and the Installation Rate of Automotive LED Lighting Approached 90...
Ecological Domain and Automotive Hardware Expansion Research Report, 2025
ResearchInChina has released the Ecological Domain and Automotive Hardware Expansion Research Report, 2025, which delves into the application of various automotive extended hardware, supplier ecologic...
Automotive Seating Innovation Technology Trend Research Report, 2025
Automotive Seating Research: With Popularization of Comfort Functions, How to Properly "Stack Functions" for Seating?
This report studies the status quo of seating technologies and functions in aspe...
Research Report on Chinese Suppliers’ Overseas Layout of Intelligent Driving, 2025
Research on Overseas Layout of Intelligent Driving: There Are Multiple Challenges in Overseas Layout, and Light-Asset Cooperation with Foreign Suppliers Emerges as the Optimal Solution at Present
20...
High-Voltage Power Supply in New Energy Vehicle (BMS, BDU, Relay, Integrated Battery Box) Research Report, 2025
The high-voltage power supply system is a core component of new energy vehicles. The battery pack serves as the central energy source, with the capacity of power battery affecting the vehicle's range,...
Automotive Radio Frequency System-on-Chip (RF SoC) and Module Research Report, 2025
Automotive RF SoC Research: The Pace of Introducing "Nerve Endings" such as UWB, NTN Satellite Communication, NearLink, and WIFI into Intelligent Vehicles Quickens
RF SoC (Radio Frequency Syst...
Automotive Power Management ICs and Signal Chain Chips Industry Research Report, 2025
Analog chips are used to process continuous analog signals from the natural world, such as light, sound, electricity/magnetism, position/speed/acceleration, and temperature. They are mainly composed o...
Global and China Electronic Rearview Mirror Industry Report, 2025
Based on the installation location, electronic rearview mirrors can be divided into electronic interior rearview mirrors (i.e., streaming media rearview mirrors) and electronic exterior rearview mirro...
Intelligent Cockpit Tier 1 Supplier Research Report, 2025 (Chinese Companies)
Intelligent Cockpit Tier1 Suppliers Research: Emerging AI Cockpit Products Fuel Layout of Full-Scenario Cockpit Ecosystem
This report mainly analyzes the current layout, innovative products, and deve...
Next-generation Central and Zonal Communication Network Topology and Chip Industry Research Report, 2025
The automotive E/E architecture is evolving towards a "central computing + zonal control" architecture, where the central computing platform is responsible for high-computing-power tasks, and zonal co...
Vehicle-road-cloud Integration and C-V2X Industry Research Report, 2025
Vehicle-side C-V2X Application Scenarios: Transition from R16 to R17, Providing a Communication Base for High-level Autonomous Driving, with the C-V2X On-board Explosion Period Approaching
In 2024, t...
Intelligent Cockpit Patent Analysis Report, 2025
Patent Trend: Three Major Directions of Intelligent Cockpits in 2025
This report explores the development trends of cutting-edge intelligent cockpits from the perspective of patents. The research sco...
Smart Car Information Security (Cybersecurity and Data Security) Research Report, 2025
Research on Automotive Information Security: AI Fusion Intelligent Protection and Ecological Collaboration Ensure Cybersecurity and Data Security
At present, what are the security risks faced by inte...
New Energy Vehicle 800-1000V High-Voltage Architecture and Supply Chain Research Report, 2025
Research on 800-1000V Architecture: to be installed in over 7 million vehicles in 2030, marking the arrival of the era of full-domain high voltage and megawatt supercharging.
In 2025, the 800-1000V h...
Foreign Tier 1 ADAS Suppliers Industry Research Report 2025
Research on Overseas Tier 1 ADAS Suppliers: Three Paths for Foreign Enterprises to Transfer to NOA
Foreign Tier 1 ADAS suppliers are obviously lagging behind in the field of NOA.
In 2024, Aptiv (2.6...
VLA Large Model Applications in Automotive and Robotics Research Report, 2025
ResearchInChina releases "VLA Large Model Applications in Automotive and Robotics Research Report, 2025": The report summarizes and analyzes the technical origin, development stages, application cases...
OEMs’ Next-generation In-vehicle Infotainment (IVI) System Trends Report, 2025
ResearchInChina releases the "OEMs’ Next-generation In-vehicle Infotainment (IVI) System Trends Report, 2025", which sorts out iterative development context of mainstream automakers in terms of infota...