我们知道,保险公司利用UBI,会构建两个分析模型,一个是驾驶风险模型,一个是基于驾驶风险和其他风险的保险定价模型。驾驶风险模型是需要拥有车联网数据具备车联网运营经验,懂驾驶行为,懂车,能够进行数据分析,一般是主机厂、TSP或者数据平台公司。保险精算模型是具备车险资质和精算经验,一般是保险公司,保险经纪公司,精算咨询服务公司。
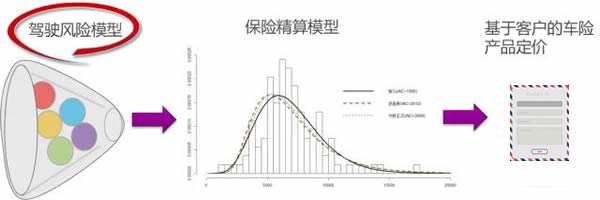
对大部分采用UBI计算的保险公司/车联网公司来说,驾驶风险模型会用到50个以上的变量,这些变量大部分是通过车联网采集,前装数据会多一点,质量好点,后装OBD的方式,有一些数据的噪音。
这些变量一般是:行驶里程,平均出行的时长、平均出行距离、平均每天出行次数、平均每天出行时间、平均一天驾驶距离、平均一周驾驶距离、周一到周五平均驾驶次数、周末驾驶次数、平均速度、急加速/百公里、急刹车/百公里、路型、各地形的行驶里程、个地形的驾驶时间、各地形的停车时间、转弯次数、横向加速次数、滚动停止、变道次数、变速频率、变速级别、巡航控制、左转弯次数、速度偏差、假期驾驶、驾驶类型(速度VS时间)、驾驶类型偏差、出行半径、交叉口次数、转弯信号灯、安全带状态、安全气囊状态、灯/雨刷状态、车辆维修状态、出行间隔、拥堵指数、手机使用等。因为各个变量之间也具备关联关系,这里我们会有基本算法的选择,是使用线性聚类,还是神经网络的决策树算法。
我们通过对一年5千辆车的运行车联网数据进行了基本的算法建立,如下图。
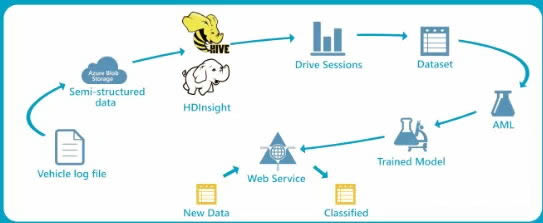
首先通过log file建立初始数据,通过云端存储进行半结构化的数据,通过HIVE和HDInsight进行数据的清理,drivesession相当于进行驾驶风险的数列化,建立基本的数据表单,通过Dataset,AML(基于云端的机器学习)和数据训练模式,形成最后的驾驶风险打分,打分的结果会通过WebService进行展示。目前车联网数据收集来源,这里很多工作是进行了数据的清洗工作。同时根据保险公司提供的理赔名单和驾驶车主进行匹配,在训练模型中进行相关的训练。
要建立一个驾驶风险的基准,一般要经过下图的几个步骤:

第一步,数据准备:
1、了解管理层对UBI的期望和策略
2、了解目前保险公司的目前的数据来源,前装/后装/其他例如APP
3、了解可以与车联网数据集成的数据来源,例如客户基本信息、理赔数据、维修数据等
4、基于数据的基本分析,确定需要达到的目标
5、整理数据,明确数据的业务定义并进行清洗,去噪
第二步,云平台验证:
1、在保险公司的协助下,从UBI的车主中选取出险理赔的红蓝匹配样本,抽取特征值,进行打标签
2、在Azure云平台构建业务模型(神经网络/决策树等)
3、数据导入,进行云平台运算,校验模型
4、和精算分析进行沟通,确定驾驶风险输出的可用性
第三步,形成模型基准:
1、根据云平台的验证结果,建立驾驶风险的评分模型
2、明确和其他数据的(例如理赔)的集成和协同关系
3、建立通过驾驶风险进行骗保、客户分群的整体架构
4、研究其他UBI保险驾驶风险模型的实施路径
5、进行蓝图设计,明确驾驶风险模型完善实施的规划
下面是经过驾驶风险打分后的结果示例:
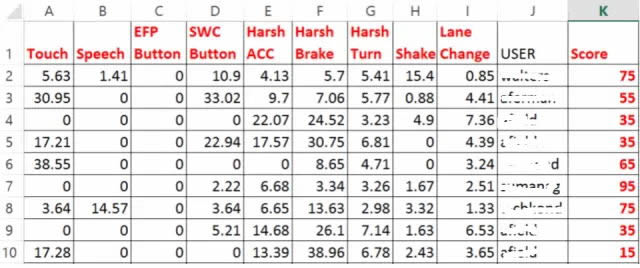
总结来看,这个整体架构和技术特点是:
1、多种数据(规则、半规则)数据的集成处理技术
2、基于云的机器学习,汇集各种算法,通过界面拖拽构建,存储成本低,数据培训快,推向用户端快
3、对实时运行的上千辆前装车联网数据进行了验证